Страницу можно вылизать до блеска — тайтл, текст, разметка, скорость, — и не получить с неё ни одного перехода. Причина чаще всего скучная: её нет в индексе. Для Яндекса и Google страница, которую не обошёл робот, просто не существует.
- Индексация — это попадание страницы в базу поисковика. Нет в базе — нет в выдаче, и говорить о позициях бессмысленно.
- Проверить статус — минута: оператор
site:для прикидки и Яндекс.Вебмастер / Search Console для точного ответа по конкретному URL. - Девять из десяти «робот не дошёл» на деле оказываются
noindexили закрытием в robots.txt, которые кто-то поставил и забыл. - Ускоряют индексацию через IndexNow, переобход в Вебмастере, свежий sitemap и внутренние ссылки на новую страницу.
Зачем это знать
SEO принято начинать с семантики, текстов и ссылок. Но всё это — борьба за место внутри индекса. Если страницы там нет, бороться не за что: ты оптимизируешь то, чего для поиска не существует.
Поэтому индексация идёт первой. Сначала убеждаешься, что робот видит страницы и кладёт их в базу, и только потом занимаешься позициями. Порядок, который экономит недели.
Что такое индексация
Поисковик не бегает по всему интернету в момент твоего запроса — это было бы слишком медленно. Он ищет по своей заранее собранной базе, индексу. Наполняет её робот-краулер: обходит страницы, скачивает, разбирает содержимое и складывает в индекс. Путь у каждой страницы один и тот же.
Индексация и ранжирование — разные вещи, которые часто путают. Индексация отвечает на вопрос «знает ли поисковик о странице». Ранжирование — «на каком месте её показать». Первое без второго бывает, второго без первого — нет.
Как проверить, в индексе ли страницы
Три способа, от быстрого и грубого к точному.
Оператор site: — быстрая прикидка
Оператор site: — десять секунд на прикидку. Введи в поиск site:твой-домен.ру и увидишь примерное число страниц в индексе. По разделу — site:твой-домен.ру/blog/. Конкретную страницу проверяют, вставив её полный адрес. Число приблизительное, Яндекс и Google округляют, но для ответа «раздел в индексе или нет» этого хватает.
# весь сайт site:pawetta.com # только раздел site:pawetta.com/blog/ # конкретная страница site:pawetta.com/blog/indeksaciya-sajta/
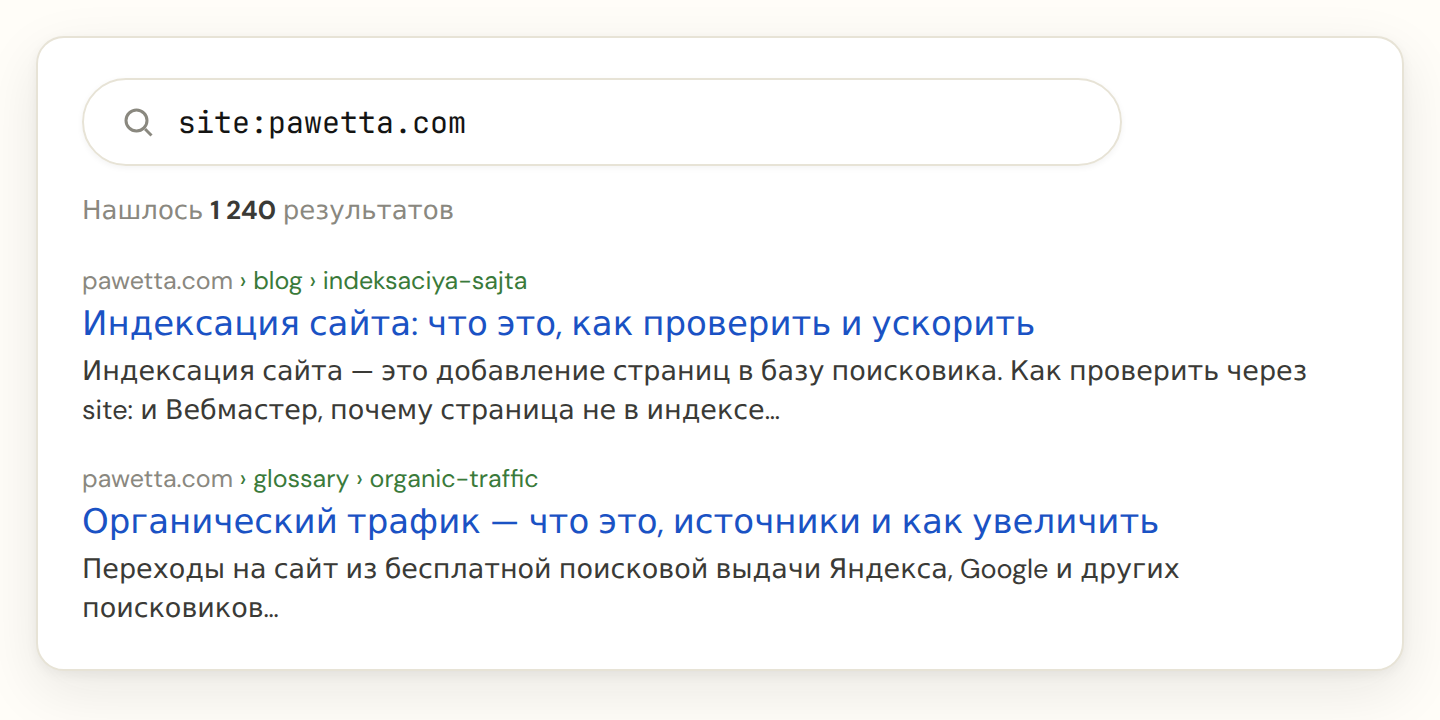
site: в выдаче: строка «Нашлось N результатов» — это примерное число страниц домена в индексе. Значения для примера.Вебмастер и Search Console — точная проверка
Яндекс.Вебмастер и Google Search Console — точный ответ. В Вебмастере раздел «Индексирование → Страницы в поиске» показывает, что реально в индексе, а «Проверить статус URL» — состояние конкретной страницы и причину, если её там нет. В Search Console то же делает «Проверка URL». Это не прикидка, а официальные данные поисковика о твоём сайте — с ними и нужно работать. Если ещё не подключил панели, начни с Яндекс.Вебмастера.
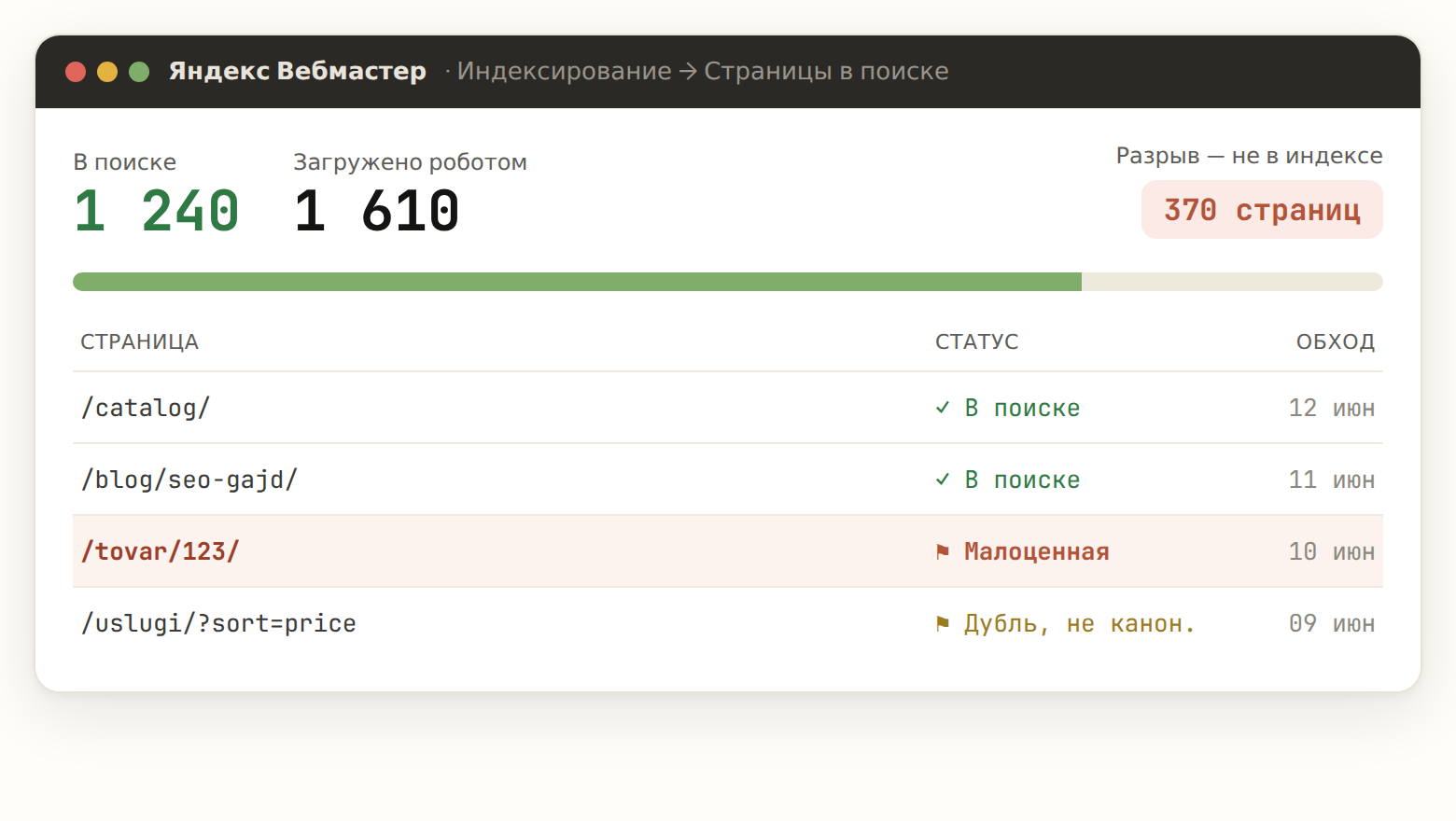
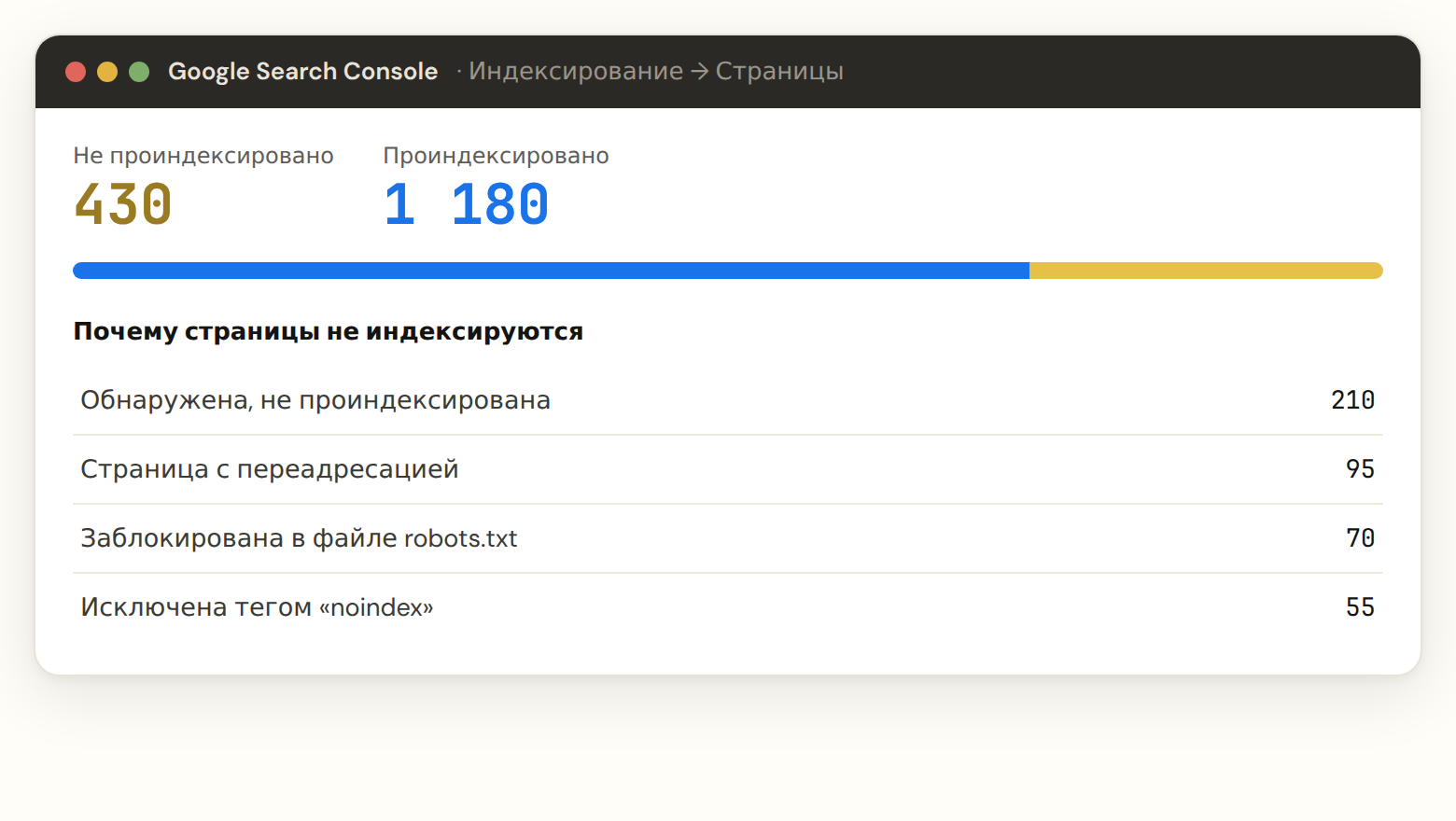
Смотри на разрыв между «загружено роботом» и «в поиске». Большой разрыв — это и есть твои незаиндексированные страницы. Именно там копать причину.
| Что нужно | Яндекс.Вебмастер | Google Search Console |
|---|---|---|
| Проверить статус URL | Индексирование → Проверить статус URL | Проверка URL (строка сверху) |
| Все страницы в индексе | Индексирование → Страницы в поиске | Индексирование → Страницы |
| Запросить переобход | Индексирование → Переобход страниц | Проверка URL → Запросить индексирование |
| Причины исключения | Страницы в поиске → Исключённые | Страницы → «Не проиндексировано» |
| Загрузить sitemap | Индексирование → Файлы Sitemap | Индексирование → Файлы Sitemap |
Почему страница не в индексе
Прежде чем винить робота, проверь, не закрыл ли ты страницу сам. По моему опыту, это первая причина в большинстве случаев «куда делась страница». Вот что встречается чаще всего.
<meta name="robots" content="noindex">. Самая частая и самая обидная причина: код стоит явно, но о нём забыли.Отдельная группа причин — коды ответа сервера. Поисковик по-разному реагирует на каждый, и от этого зависит, останется страница в индексе или выпадет. Проверить ответ можно в Я.Вебмастере, GSC или командой curl -I.
| Код | Что значит | Что делает поисковик |
|---|---|---|
| 200 | Страница отдаётся нормально | Обходит и индексирует |
| 301 | Постоянный редирект | Склеивает со страницей-целью, передаёт ей сигналы |
| 302 | Временный редирект | Оставляет в индексе исходный URL — для переезда не годится |
| 404 | Страницы нет | Со временем убирает из индекса — не сразу |
| 410 | Удалена навсегда | Убирает из индекса быстрее, чем при 404 |
| 503 | Временно недоступна (техработы) | Откладывает обход и возвращается позже; позиции не теряются, если ненадолго |
Если хочешь убрать страницу из поиска — закрывай её правильно: тегом noindex, а не строкой в robots.txt. robots.txt запрещает обход, но не индексацию: страница может остаться в выдаче без сниппета, со служебной подписью вместо описания. Логика контринтуитивная, но именно так это и работает.
JavaScript и mobile-first: почему современные сайты не индексируются
Две причины, которые не видны в исходном коде и потому особенно коварны. Сайт выглядит нормально в браузере, а робот его не индексирует — потому что робот смотрит на страницу иначе, чем ты.
JavaScript-рендеринг
Если контент подгружается скриптом уже после загрузки страницы (типичная история для сайтов на React, Vue, Angular и части конструкторов), робот может увидеть пустой каркас без текста. Яндекс JS исполняет ограниченно, Google — лучше, но с задержкой и не всегда полностью. Итог: страница в индексе есть, а текста в ней для поиска нет, либо она висит в статусе «обнаружено, не проиндексировано».
Лечится серверным рендерингом (SSR) или пререндером — чтобы робот получал готовый HTML с контентом сразу. Проверить, что именно видит поиск, можно через «Посмотреть, как робот» в инструментах Вебмастера и Search Console: если в отрендеренном HTML текста нет — проблема подтвердилась.
Mobile-first индексация
Google индексирует и ранжирует мобильную версию страницы, а не десктопную. Если на мобильной версии часть контента скрыта, урезана или вынесена под клик, для индекса этого контента фактически нет. Поэтому адаптив должен отдавать тот же текст и те же ссылки, что и десктоп, — не «облегчённую» версию. Яндекс отдельного mobile-first индекса не вводил, но мобильное удобство учитывает в ранжировании, так что правило универсальное.
Краулинговый бюджет — что это и как не сливать
Краулинговый бюджет — это сколько страниц робот готов обойти на сайте за единицу времени. Ресурс конечный: он зависит от авторитета домена, скорости ответа сервера и того, как часто меняется контент. Для сайта на 200 страниц это не проблема — робот обойдёт всё. Для крупного проекта на десятки тысяч URL бюджет становится узким горлышком.
Пример: у интернет-магазина 50 000 страниц фильтров и сортировок. Робот тратит обходы на этот мусор, а до нужных категорий и карточек добирается раз в месяц. Снаружи выглядит как «Яндекс не индексирует» — на деле бюджет сливается на хлам.
Как не сливать бюджет: закрой от индекса дубли, пагинацию и бесконечные комбинации фильтров (через noindex, canonical или robots.txt — смотря по задаче), держи в sitemap только живые полезные URL, ускорь ответ сервера и выстрой перелинковку так, чтобы важные страницы были в 2–3 кликах от главной. Тогда робот тратит обходы на то, что должно быть в поиске, а не на технический балласт.
Как настроить индексацию правильно
Управление индексацией держится на трёх файлах и тегах. Разберём, за что отвечает каждый и как не выстрелить себе в ногу. Подробный разбор первых двух — в отдельном гайде про robots.txt и sitemap.xml.
robots.txt — что разрешить, что закрыть
Это инструкция для робота, куда ходить можно, а куда нельзя. Закрывают служебные разделы (корзина, личный кабинет, результаты поиска по сайту, дубли с параметрами). Главная ошибка — закрыть Disallow: / на тестовом домене и забыть снять после переноса на боевой: тогда из индекса вылетает весь сайт. И помни: robots.txt запрещает обход, но не выкидывает из индекса — для этого нужен noindex.
sitemap.xml — как сделать правильно
Карта сайта — это список URL, которые ты хочешь видеть в индексе, с датами изменения. В неё попадают только живые страницы, отдающие код 200: без редиректов, без закрытых в noindex, без дублей. Честный lastmod помогает роботу понять, что обновилось. Sitemap нужно указать в robots.txt и загрузить в обеих панелях вебмастера.
canonical — когда и как ставить
Тег canonical говорит поисковику, какая из похожих страниц главная. Ставят его на страницах с фильтрами, сортировками, UTM-метками и пагинацией — чтобы вес собирался на одной канонической версии, а дубли не плодились в индексе. На уникальной странице canonical указывает сам на себя — это нормально и правильно.
Как ускорить индексацию
Когда со страницей всё в порядке и она просто ждёт своей очереди, обход можно поторопить. Магии тут нет — есть несколько рабочих способов, которые стоит применять вместе.
Чего точно не нужно делать — покупать «прогон по индексации» и сервисы быстрого добавления страниц. В лучшем случае деньги на ветер, в худшем — лишний след, который поисковику не нравится. Если страница хорошая и открыта для обхода, она проиндексируется и так.
Как закрыть страницу от индексации
Обратная задача: страница есть, но в поиске ей не место — служебная, дубль, временная или устаревшая. Способов три, и они не взаимозаменяемы: каждый решает свою задачу. Самая частая ошибка — закрыть в robots.txt то, что нужно убрать из индекса. Не сработает: robots.txt запрещает обход, но уже проиндексированная страница может остаться в выдаче.
| Способ | Что делает | Когда применять |
|---|---|---|
| meta noindex | убирает страницу из индекса, обход разрешён | страница нужна людям, но не нужна в выдаче |
| robots.txt Disallow | запрещает обход, но не гарантирует выход из индекса | служебные разделы, которые робот не должен сканировать |
| 410 Gone / 404 | сообщает, что страницы больше нет | страница удалена навсегда |
noindex. Нужно запретить обход — robots.txt. Страницы больше нет — отдавай 410. Не путай задачи.Важный нюанс: чтобы noindex сработал, робот должен сначала зайти на страницу и увидеть тег. Если ты одновременно закроешь её в robots.txt, робот туда не зайдёт, тег не прочитает — и страница так и останется в индексе. Поэтому два способа вместе не применяют: либо noindex с открытым обходом, либо robots.txt.
Мифы об индексации
Четыре заблуждения, из-за которых теряют время и деньги. Разберём, как на самом деле.
Частые вопросы
Как проверить, проиндексирована ли конкретная страница?
Сколько времени занимает индексация сайта?
Почему страница пропала из индекса?
Как закрыть страницу от индексации?
Сколько страниц должно быть в индексе?
Влияет ли индексация на позиции в выдаче?
Что такое краулинговый бюджет?
Почему сайт на JavaScript плохо индексируется?
Главное
Проверь индекс через site: и Вебмастер. Если страниц меньше, чем нужно, первым делом ищи noindex и закрытие в robots.txt — а не вини робота. Когда со страницей всё в порядке, ускорь обход через IndexNow, переобход и внутренние ссылки. Индексация — не фактор ранжирования, а вход в игру: без неё остального просто нет.
Сайт в индексе, а трафика всё равно нет? Это уже вопрос к технике и контенту целиком — разберу на SEO-аудите: покажу, что закрыто, что дублируется и что чинить в первую очередь.